SR Queue Consumer Pattern
FIFO in a Galaxy Far Far Away
The Smugglers Run Queue Consumer (SRQC) is a First In First Out (FIFO) message queue consumer that increases system throughput using parallel message processing. Its primary benefit is low overhead to maintain message order. It is particularly efficient in message transformation use cases when transformation is isolated and the transformation time is a significant portion of the overall handling cycle.
It was partially inspired by Disney’s Millennium Falcon: Smugglers Run.
This document assumes some level of familiarity with message orientated middleware and Enterprise Integration Pattern concepts.
TL;DR
By encapsulating messages processing in a per message thread container, and placing the containers into a queue we benefit from parallel processing while only monitoring the last message in the queue to maintain FIFO order.
The system is most beneficial in systems where message transformation is a significant component of overall throughput. It is not practical for systems where processing has side effects.
View the readme for a quickstart.
Background
Millennium Falcon: Smugglers Run is an interactive motion simulator ride that puts a crew of 6 riders into the cockpit of the Millennium Falcon. An imaginative component of the ride is its loading and segmentation which allow for high throughput of riders (lower wait times) with an immersive loading experience.
Each crew waits their turn in the chess room of the Millennium Falcon before being loaded into their individual ‘cockpit’. To create the experience and the short(er) wait times there are 4 ride turntables each with 7 pods, where each pod encapsulates the ride experience for a crew. The turntable rotates the pods to the riders to maintain the sense that you are walking from the chess room into the cockpit.
This article has a detailed description (apologies if you hit a paywall). There is another, shorter description available. Finally, the patent is also available.
The analogous takeaway for message processing is that if we keep the messages in order on the ‘turntable’ we can process them in a pod ‘the ride’ along with others and unload them at the end.
Introduction
In a system that requires FIFO message processing improving throughput when transformation time is a significant bottleneck leaves a few popular choices:
- Process messages using a competing consumer pattern with a SequenceId that re-assembles the order in a post processing step. While efficient this requires additional re-assembly of message order and complicates error handling.
- Partitioning messages within a queue(s) to support parallel processing of each. Assuming partitioning is feasible for a use case, the speed for the entire population of messages increases, however messages in a partition are still handled serially.
Taking inspiration from the segmented turntable described above a system is presented here that is able to increase throughput, maintain FIFO order, and eliminate any re-assembly. Multiple messages are transformed at a time as they ‘move’ from entry to exit. They exit in the same order they arrived, but experienced the ride (transformation) separately.
Operation
The system contains a configurable number of pods that each process a message via an assigned thread. The system loads and unloads the pods in order via a dedicated queue, referred to as the conduit. If a message finishes processing before it reaches the exit it simply waits. When a message reaches the end of the conduit it is unloaded into an outbound queue. If a message reaches the exit before it has completed the unload operation waits for completion, unloads it, and messages continuing flowing through the system.
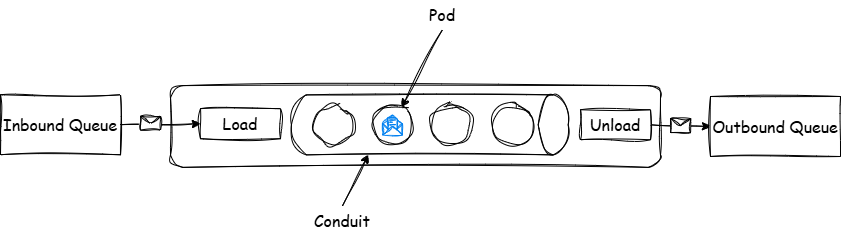
So hypothetically if a message takes 100 msec to process then our maximum message rate is 10 messages per second if processed in a serial manner, however if we can process 3 ‘pods’ at a time we increase our rate to 30 messages per second. While we will not see the theoretical throughput due to sequencing overhead and message timing variation, we will see a significant improvement compared to serial processing.
| Component | Description |
|---|---|
| Pod | Container that processes the message from inbound to outbound format on a thread. |
| Conduit | An organizational construct to maintain messages in their received order while they are processing. |
| Message Loading | Place waiting messages into a pod for processing. |
| Message Unloading | Monitors pods at the exit. If the message transformation is completed the message is put in the outbound queue. If it is still processing it will wait for completion. |
| Inbound Queue | A typical inbound queue in a Message Orientated Middleware (MOM) style application. Simulated as an in memory array. |
| Outbound Queue | A typical outbound queue in a Message Orientated Middleware (MOM) style application. Simulated as an in memory array. |
Pod count is a balance between consumed resources, context switching efficiency, and ‘at risk’ messages. ‘At risk’ messages in this context refers to overhead required for handling failures. Assuming the inbound queue and outbound queues are resilient the more in flight messages we release the more care must be taken for message processing or system failures.
Limitations
A few notable limitations to the system.
- Diminishing returns as the message process time reduces. Eventually the overhead of synchronization hampers performance.
- Performance degradation by ‘long pole’ messages. Messages that take a significantly longer amount of time to process than their peers may drag down the throughput relative to a re-sequencing competing consumer pattern.
- By allowing a greater number messages into the system simultaneously we lose some of the message resilience the inbound queue provides.
- The transformation of the message must be self contained, I.e. the only target is the exit queue. If any portion of the processing has external side effects that include FIFO restrictions this pattern would not suffice since there is no synchronization of ‘in flight’ transformations.
Running the Project
For the demonstration project the message transformation is simply a string update and a Thread.Sleep() to simulate processing time.
Please refer to the project Readme for details on running the project.
When the simulation finishes running a summary is logged. The output will resemble the following (timestamps and log level omitted):
010012:002:0000193:New outbound message is: 12 from pod 37c52e90-0f27-4476-8c0a-a9bf73b629cd
Where the columns are ‘:’ delimeted, representing:
- The first column is the message id
- The second column is the index of the pod that processed the message
- the third is the configured delay (message processing simulation)
- The fourth column is the transformed message.
The last line will contain summary information
2 Total processing time: 721.4762 msec. Accumulated 'Serial' Time: 2066 msec. Ratio: 2.863573323693838
That includes:
- Total processing time is the start to finish of the execution.
- Accumulated ‘Serial’ Time represents the time it would take to process all messages serially.
- Ratio is the Accumulated / Total; the estimated throughput improvement.
Next Steps
The project as it sits today is mostly for demonstration, following are a few next steps to consider for a more robust system.
- Externalize the Types and logic for the pod and conduit. By templatizing the types for inbound and outbound messages and externalizing the pod processing logic the system can be re-used.
- Error Handling Patterns. What happens when a message fails, what should ripple upstream.
- Run as an IHostedService.
- Incorporate a common message queue, I.e. rabbitmq.
Summary
In the end this project was primarily a thought exercise, however it was successful with the requirements that I had envisioned for it, namely:
- speeding up processing of a FIFO queue where the bottleneck was the message processing itself.
- not adding any external complexities to maintain message order.
If nothing else it was an opportunity to look at a problem with a different lens and see what comes of it.
Your mileage may vary.